
データの縦持ち・横持ち
データマネジメントの電子化は、臨床データの収集をよりタイムリーに、より確実に行うためです。そして、試験・研究でデータを収集する目的は、それをどこかでまとまりのある形で出力して、解析にまわすためです。試験終了まででも、プロトコルに定められている中間解析か、あるいは学会発表があるので現時点での基本統計量を出したいなど、「データ出してくれ」というご用命は(特に臨床研究においては)データセンターにいつ降りてくるかわかりません(本当は「いつ降りてくるかわからない」はまずいのですが…ちょっと割愛)。今回はデータの出し方において、解析の方と仲良くなれるためのキーワード「横持ち・縦持ち」についてです。
横持ちのデータ
誰かに名簿の表(テーブル)を作らせるとしたら、9割の人は列の見出しに、ID、氏名、性別、住所等々の情報を入れ、基本的には一人の情報が一行に収まるような構造を作成すると思われます。

この形式の表は、内容がコンパクトに収まるので、紙媒体や画面上で表示したときの検索性が優秀です。その反面、項目を加えたりすると、列を加えなければいけない都合上、テーブルの構造事態が変化してしまいます。こういった構造のテーブルは、「非正規化テーブル」と呼ばれることもあります。
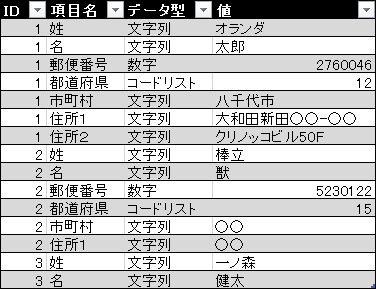
縦持ちのデータ
横持ちのデータでは、名簿の例だと一行に一個人、というデータの格納の仕方をします。縦持ちのデータでは、一個人のデータが複数行に分けられます。列の見出しには、ID、項目名、データ型、値、が入ります。そして各行には、項目名が「姓」なら値に「姓の文字列」、項目名が郵便番号なら「7桁の数値データ」、等々が格納されます。メタデータことデータの各種属性と、値とが同じ表に収まっている状態です。

この形式のメリットはいくつかあります。一つ目は、データ型等の情報が同じテーブル内にあるので、解析ソフトに取り込みときにデータ型の設定が簡単に出来ること。二つ目は、存在しないデータについては行を作成しなくて良いので、横持ちのテーブルでは仕方の無かった無駄な空欄が生じないこと。そして三つ目に、項目が追加された場合も列の数自体は変わらないこと、が挙げられます。こういった構造のテーブルは、「正規化テーブル」と呼ばれることもあります。
データの正規化≠テーブルの正規化
一点、用語についての注意です。少々ややこしい話なのですが、同じ「正規化」という単語でも、データ全体を指して言う場合と、テーブルを指して言う場合とでは意味合いが大きく異なります。従いまして、データの受け渡し方について話し合う時は、「正規化」では無く、「縦持ち」という言い方をした方が良い場合もあります。
縦持ちが好まれるわけ
EDCあるいはCDMSで蓄積されたデータは、どこかの時点で解析のため出力される必要があります。解析を行う側は、出力されたデータを専用の解析ソフトに取り込みますが、縦持ちのデータだとデータ型や単位、基準値上下限等の情報がデータ項目単位で一行に並びます。そのため、取り込む際に解析ソフト側にもデータの属性を伝える(プログラミングする)のが楽になります。横持ちのデータでは、別途データの属性の情報が入ったテーブルが必要になります。
また、データ項目を加えた場合も、横持ちだと列が新たに作られるため、解析ソフトに取り込むプログラムを見直さなければいけなくなる場合があります。縦持ちだと、行を挿入するだけで、解析ソフトへの取り込みは同じプログラムを再利用できます。
一目見たときの検索性が優れないため、少々とっつきにくく感じられるものだと思いますが、アーカイブするものとしても、加工するベースとしても、縦持ちのデータの方が汎用性は高いです。尚、近年巷で話題のSDTMも、基本的に縦持ちの構造です。








コメント